دیتاست به مجموعه ای از داده ها اطلاق می شود، که هر مورد آن(هر سطر از آن) به نمونه مستقلی اختصاص دارد. هر ستون ویژگی یا داده ای خاص از هر نمونه می باشد. فرض کنید دیتاستی از مشخصات ظاهری افراد را داشته باشیم. هر سطر از این دیتا ست مربوط به یک نفر می باشد. مثلا سطر اول برای محمد، سطر دوم برای مهدی و ... ستون های دیتاسیت نیز هر کدام ویژگی خاصی را توصیف می کنن، مثلا ستون اول قد، ستون دوم وزن و ... همین تعداد سطرها و ستون ها مهمترین ویژگی دیتا ست ها هستند که به آن تعداد نمونه و تعداد ویژگی گفته می شود. اگر بخواهیم دیتاست را به صورت جدول نمایش بدهیم، شکلی شبیه زیر خواهد داشت.
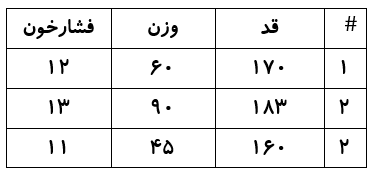
ممکن است دیتا ست لیبل گزاری شده باشد(عنوان دار باشد). برای نمونه دیتاست فوق را در نظر بگیرید که اطلاعاتی نظیر وزن و قد وفشار خون افرادی را نمایش می دهد، حال چنانچه مشخص گردد، هر سطر این دیتا ست به یک زن یا مرد اختصاص دارد، این دیتا ست نوعی دیتا ست لیبل گزاری شده می باشد.
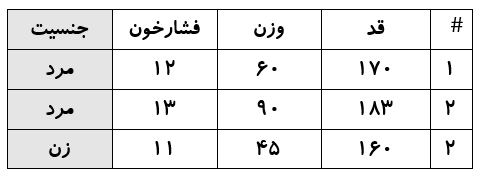
دیتاست ها امروزه بیشتر در بحث هوش مصنوعی و یادگیری ماشین کاربرد دارند. با استفاده از این دیتاست ها مدل های هوشمندی توسعه داده می شوند، تا کار خاصی را انجام دهند. مثلا چنانچه به نمونه فوق بازگردیم، می توان با این دیتاست مدلی را توسعه داد، که بتواند با دریافت قد و وزن و فشار خون جنسیت صاحب ویژگی ها را حدس بزند.